主なデータ型
- NUMBER:整数と少数
- CHAR(n):nバイトの固定長文字列
- VARCHAR2(n):nバイト以下の可変長文字列
- BLOB:バイナリデータ(最大128テラバイト)
- CLOB:文字列(最大128テラバイト)
- DATE:年月日時分秒のデータ
- TIMESTAMP:年月日時分秒に少数秒を加えたデータ
列別名
ORDER BY句では列別名を利用して列を指定できるが、それ以外ではエラーとなる。
列別名はシングルクォーテーションは不要だが、スペースや特殊な記号、大文字/小文字を区別する場合、先頭の文字がアルファベット以外の場合にはダブルクォーテーションで囲む必要がある。
常にダブルクォーテーションで囲んでおいたほうが安全。
SELECT <列名> AS <列別名> FROM <テーブル名>;
文字列
文字リテラル
文字列をシングルクォーテーションで囲んだもの。
例)'person'
データとしての文字列そのものを表す。
【重要】
ダブルクォーテーションとの用途の違いに注意!
ダブルクォーテーションの利用は、列名、列別名、オブジェクト名の指定の際に、特殊文字や大文字/小文字を区別する場合や先頭の文字がアルファベット以外の場合に限る。
文字リテラル内でのシングルクォーテーションの利用
文字列内にシングルクォーテーションを含む場合にはシングルクォーテーションでエスケープできる。
つまり、'I'll go to'を'I''ll go to'と記述することでシングルクォーテーションを文字リテラルとして認識させることができる。
あるいは、q'[I'll go to]' や q'|I'll go to|' と記述してもシングルクォーテーションを文字列として認識させることができる。
文字列の連結
||という記号を使うと2つも文字列を連結できる。
特殊なテーブル
DUALテーブル
- データベース作成時に自動的に作成されるテーブル
- すべてのユーザが読み取り可能
- 用途は定数を含む式の表示やファンクションの結果表示
SELECT 365*5 FROM dual;
日時データ
次のいずれかの方法で日時データを得ることができる。
- TO_DATEファンクションを利用する
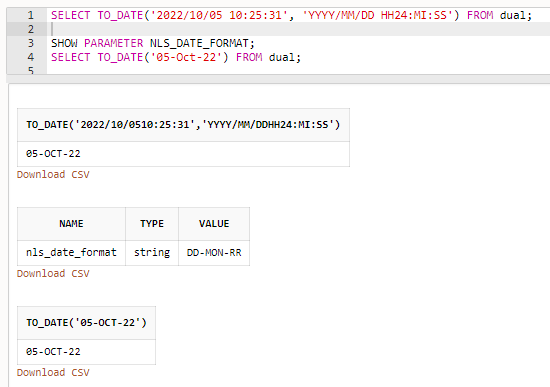
- TO_DATE('2022/10/05 10:25:31', 'YYYY/MM/DD HH24:MI:SS')
- TO_DATE('05-Oct-22') ※ NLS_DATE_FORMATパラメータの書式モデルに基づく
- 文字列をDATE型の列に挿入することで暗黙的に変換 ※文字列はNLS_DATE_FORMATパラメータの書式モデルに従っていないといけない
日時データの書式モデルには次のようなものがある。
コマンド
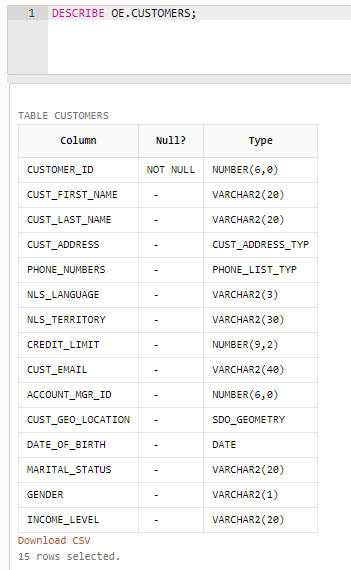
DESCRIBE (DESC)
列名、データ型が確認できる。
NULLの扱い
Oracleでは空文字(長さゼロの文字列)はNULLとして扱われるので要注意。
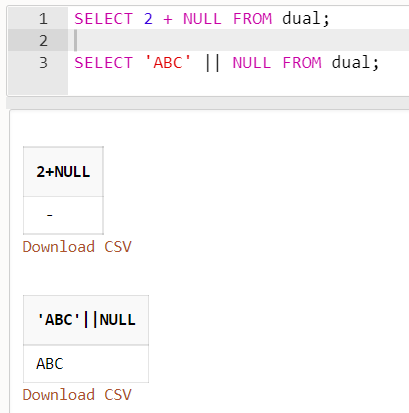
また、NULLを含む算術式は常にNULLと評価される。2 + NULLはNULLとなる。
ただし、NULLと文字列を結合した場合は文字列となる。'ABC' || NULLは'ABC'となる。
SQLでは真理値が真、偽、不明(Unknown)の3値となっている。
NULLとなっているレコードを比較演算子で比較すると結果は"不明"となる。
そこで、NULLとなっているレコードを探す場合にはWHEREでIS NULL または IS NOT NULL条件を使う。
書籍中では、
可能な限り列値にNULLやから文字列を設定せず、数値データであれば0、文字列であれば「未使用」という文字列~中略~を設定することをお勧め
している。
※注釈※
BigQueryの場合だと、カラムナテーブルということもありNULLが多い(疎になっている)方が圧縮が効いたりするので、↑のベストプラクティスはあくまでOracleの場合と捉えたほうが良さそう。
検索条件
WHERE句で利用できる検索条件たち。
ソート
ORDER BY句によるソートは、列名に加えて列の一番号、列別名も使用できる。複数の列でソートすることも可能。
NULLは昇順だと末尾に表示される。降順だと先頭に表示される。
置換変数
DEFINE <変数名> = <値>
で定義して、&<変数名>、&&<変数名>で参照する。
DEFINEを使用しない場合、置換変数の値を入力するよう求められる。
&<変数名>は参照の度に都度入力を求められる。
&&<変数名>の場合は一度だけ入力を求められる。
組み込み関数
以下を参照のこと。
データ型変換
暗黙的な型変換は型変換が実行されていることを把握しにくいため、トラブルにつながる恐れがある。
また、将来のリリースで動作が変更される可能性がある。
以上のことから、ファンクションを使用した明示的な型変換が望ましい。
TO_CHAR()、TO_NUMBER()、TO_DATE()がある。

集計ファンクション
集計ファンクションには、MAX, MIN, SUM, COUNTなどがある。
集計ファンクションの引数の列にNULLが含まれる場合、NULLは集計対象外となる。
AVGを使用する場合は、NULLに要注意。NULLとなっているレコードは母数に含まれない。
NULLのレコードも含めて集計したい場合は、NVLファンクションを使用すると良い。
AVG(NVL(point, 0))とすることで、point列にNULLが含まれていても0に変換したうえで平均を集計してくれる。
一方、SUM、MIN、MAXであれば、NULLが存在していても大して問題ない。
但し、COUNTで引数にアスタリスクを指定した場合、つまりCOUNT(*)とした場合には、NULLであってもカウントされる。
GROUP BY句
指定した列でグループ化される。複数列の組み合わせでグループ化することもできる。
GROUP BY句と一緒にWHERE句を使用する場合、グループ化前にWHERE句のフィルターが適用される。
一方、HAVING句はグループ化後にグループ毎の集計結果に対してフィルターを適用できる。
GROUP BY句による集計ファンクションのネスト
以下の例ではGROUP BY句で部署毎の平均を求めてから、部署毎の平均値の最大を求めている。
このようにネストすることができる。
SELECT MAX(AVG(salary)) FROM employees GROUP BY dept;
結合
2つのテーブルを結合して列を増やす、というイメージ。
結合方法は次の5種類がある。
結合を繰り返すことにより、3つ以上のテーブルを結合できる。
INNER JOIN(JOIN):内部結合LEFT OUTER JOIN:左外部結合RIGHT OUTER JOIN:右外部結合FULL OUTER JOIN:完全外部結合CROSS JOIN:クロス結合(デカルト積)
ON句の代わりにUSING句を使用することもできるが、結合する2つのテーブル間で結合に使用する列名がが同じでなければならない。
JOIN句の前にNATURALをつけて、
NATURAL INNER JOIN(JOIN)NATURAL LEFT OUTER JOINNATURAL RIGHT OUTER JOINNATURAL FULL OUTER JOIN
とすることもできる。
その場合、結合する2つのテーブル間で列名とデータ型が同じでなければならない。
WHERE句を用いた内部結合
以下のようにJOIN句を用いずにWHERE句で内部結合ができる。
FROM句にテーブルをカンマ区切りで記述する。
SELECT ... FROM table1, table2 WHERE table1.column1 = table2.column1
もし、WHERE句の結合条件を省略した場合にはクロス結合となる。
つまり、以下と同義。
SELECT ... FROM table1 CROSS JOIN table2;
ON句に'='の代わりにBETWEENを用いる
SELECT ... FROM table1 JOIN table2 ON table1.col1 BETWEEN table2.col1 AND table2.col2
副問合せ
SELECTの問い合わせ結果(副問合せ)を、WHERE句の条件に用いる。
副問合せはいくつかのパターンに分類することができる。
詳細な説明は省く。
非相関副問合せ
- スカラー副問合せ
- 最もシンプルな副問合せ。問合せの結果が単一の値になっている。
- 非スカラー副問合せ
- 副問合せの結果が複数行になっており、WHERE句に
IN、ANY、ALL、EXISTS`を用いる。 - あるいは、副問合せの結果が複数列になっている。
- 副問合せの結果が複数行になっており、WHERE句に
相関副問合せ
- 相関副問合せ
- 異なる2つのテーブル間の副問合せ
- 自己相関副問合せ
- 同じテーブルを創刊させた副問合せ
EXISTS句については、以下を参考にすること。
SQL EXISTS句のサンプル(存在判定/相関副問合せ) | ITSakura
集合演算
結合が列を増やすイメージなのに対し、2つ以上のテーブルに対して集合演算をすることで行を足したり減らしたりするイメージ。
集合演算子には次の4種類がある。
- UNION ALL:和集合 ※但し、それぞれのテーブルの重複する行を含むことに注意
- UNION:和集合
- INTERSECT:積集合
- MINUS:差集合 ※2つのテーブルの演算順序によって結果が異なる
構文は次の通り。
SELECT ... FROM table1 WHERE ... UNION SELECT ... FROM table2 WHERE ...
注意事項!!
- 各SELECTの列数とデータ型を一致させる(列数が足りない場合は、NULLや
NONE、0といったダミーデータを入れる) - 列名は異なっていても大丈夫
DML
INSERT、UPDATE、MERGE、DELETEによりデータ操作を行う。
INSERT
指定したテーブルに行(レコード)を挿入する。
副問合せを使用して複数の列や行を一度に挿入できる。
マルチテーブルINSERT
無条件 INSERT
複数のテーブルにレコードを挿入する
INSERT ALL INTO table1 VALUES (v1, v2) INTO table2 VALUES (v3, v4)
条件付きINSEART
- INSERT ALL:条件を満たす全てのWHEN句についてレコードを挿入する
- INSERT FIRST:条件を満たす最初のWHEN句についてレコードを挿入する
INSERT [ ALL | FIRST ]
WHEN condition1
THEN INTO table1 VALUES (v1, v2)
INTO table2 VALUES (v3, v4)
WHEN condition2
THEN INTO table3 VALUES (v5, v6)
INTO table4 VALUES (v7, v8)
MERGE
MERGE文により、元テーブルにユニークなキーを持つレコードが存在する場合は値を更新し、存在しない場合は新たに行を挿入する。
更新処理(UPDATE)の代わりに、削除処理(DELETE)をを指定することもできる。
MERGE INTO table1
USING table2
ON table1.col = table2.col
WHEN MATHED THEN
UPDATE SET table1 .colX = table2.colX
WHEN NOT MATHCED THEN
INSERT (table1.colA, table1.colB, table1.colC)
VALUES (table2.colA, table2.colB, table2.colC)
トランザクション
複数のテーブル間のデータの整合性を保つための機能。
DML文(INSERT、UPDATE、MERGE、DELETE)を実行すると自動的にトランザクションが開始される。
SET TRANSACTION文によって明示的にトランザクションを開始することもできる。
SET TRANSACTION NAME 'salary_update';
COMMITを実行すると変更が確定される。
COMMIT;
あるいは接続を正常に終了したときや、DDLが発行されたときも変更が確定される。
COMMIT前にROLLBACKを実行することで変更処理を取り消すことができる。
ROLLBACK;
接続が異常終了したときも変更処理が取り消される。
セーブポイント
トランザクション開始後にSAVEPOINTを実行すると、ROLLBACK TOによりセーブした点に戻ることができる。
# セーブしたいところでSAVEPOINTを定義 SAVEPOINT save1; # セーブポイントに戻る ROLLBACK TO save1;
読取り一貫性
SELECT文を実行した時点でコミットされていたデータが返される。
Oracleではコミット前のデータをUNDOデータ(ログ)として保管している。
UNDOデータを使用して、トランザクションのロールバックや読取り一貫性、リカバリを実現している。
索引(インデックス)
索引(インデックス)を作成し、索引列を検索条件に入れることでSQLを高速化できる。
CREATE [UNIQUE] INDEX <索引名> ON <テーブル名> <列>, ..., <列>
複数の列に対して作成した索引をコンポジット索引と呼ぶ。
UNIQUEを指定すると一意索引となる。一意索引とは索引列の値に重複がないことを保証するもの。
だが、通常は一意索引を使わない。なぜなら、主キー制約 (PRYMARY KEY) または一意制約 (UNIQUE)が設定された列には自動的に一意索引が作成されるため。
検索にマッチするデータの件数が少ない場合のみ高速化できる。
多数の索引を作成すると、行データ更新時に負荷が増加するので要注意。
索引の削除
DROP INDEX <索引名>;
索引の使用不可
一時的に使用しない索引を使用不可にすることで、索引セグメントを削除し、領域を解放できる、
データディクショナリに定義は残る。
ALTER INDEX <索引名> UNUSABLE;
索引の不可視化
一定期間索引を不可視化して動作状況を確認して問題なれば、索引を削除するといった運用に使用することができる。
ALTER INDEX <索引名> [ INVISIBLE | VISIBLE ];
シーケンス
シーケンスを使うと、簡単に一意な連番を振り出すことができる。
CREAE SEQUENCE <シーケンス名> START WITH <初期値> INCREMENT BY <増分値> MAXVALUE <最大値> [CYCLE | NO CYCLE] [CACHE <キャッシュ数> | NO CACHE];
CYCLEを指定すると最大値に達したときに初期値に戻る。
NO CYCLEの場合、最大値に達するとそれ以上値が生成されない。エラーにはならない。
CACHEによりメモリ上にキャッシュするシーケンスの値の数を指定できる。
連番を振り出すには<シーケンス名>.NEXTVALとする。INSERT文の値として、<シーケンス名>.NEXTVALを入れる。
振り出された連番を確認するには<シーケンス名>.CURRVALとする。
シーケンスを削除するにはDROP SEQUENCE <シーケンス名>;とする。
ロールバックしても振り出し済みのシーケンス値は戻らないため連番に空きができる可能性があることに注意。
シノニム
テーブル、ビュー、シーケンス、ファンクション、プロシージャといったオブジェクトにつける別名のこと。
指定したオブジェクトにシノニムを作成するには次の文を実行する。
CREATE [ OR REPLACE ] [ PUBLIC ] SYNONYM <シノニム名> FOR <オブジェクト名>;
プライベートシノニムを作成するにはCREATE SYNONYMシステム権限が必要。
パブリックシノニムを作成するには、CREATE PUBLIC SYNONYMシステム権限が必要。
プライベートシノニムは所有ユーザーのスキーマに格納される。所有ユーザーとシノニムが指すオブジェクトにアクセスできるユーザーが、プライベートシノニムにアクセスできる。
パブリックシノニムはどのユーザーからでもアクセスできる。但し、シノニムが指すオブジェクトへのアクセス権限は必要。
シノニムの削除は DROP [ PUBLIC ] SYNONYM <シノニム名> とする。
オブジェクトと列の命名規則
- 長さは128バイト以下
- 最初の文字はアルファベット
- 最初の文字がアルファベット以外の場合はダブルクォーテーションで囲んで表記が必要
- 大文字小文字は区別されない。区別したい場合はダブルクォーテーションで囲む
- 英数字、$、_、#以外の文字を使用した場合は、ダブルクォーテーションで囲む。つまり、日本語を使用した場合はダブルクォーテーションで囲む必要がある
制約
テーブル作成時に列毎に、またはテーブルレベルに以下の制約を指定できる。
- DEFAULT
- 列にデフォルト値を設定できる。INSERT時に指定がない場合にデフォルト値が挿入される。
- NOT NULL
- UNIQUE
- PRIMARY KEY
- CHECK
- FOREIGN KEY
列毎に制約を設定する場合の例
CREATE TABLE <テーブル名>
<列名> <データ型> [ CONSTRAINT <制約名> ] DEFAULT <デフォルト値>,
<列名> <データ型> [ CONSTRAINT <制約名> ] NOT NULL,
<列名> <データ型> [ CONSTRAINT <制約名> ] UNIQUE,
<列名> <データ型> [ CONSTRAINT <制約名> ] PRIMARY KEY,
<列名X> <データ型> [ CONSTRAINT <制約名> ] CHECK ( <列名X> > 100),
<列名> <データ型> [ CONSTRAINT <制約名> ] REFERENCES <親テーブル名> (<列名>, ... , <列名>) [ ON DELETE { CASCADE | SET NULL} ],
テーブルレベルで制約を設定する場合の例
CREATE TABLE <テーブル名>
<列名A> <データ型>,
<列名B> <データ型>,
<列名C> <データ型>,
[ CONSTRAINT <制約名> ] UNIQUE (<列名>, ... , <列名>),
[ CONSTRAINT <制約名> ] PRIMARY KEY (<列名>, ... , <列名>),
[ CONSTRAINT <制約名> ] CHECK ( <列名A> >= <列名B>),
[ CONSTRAINT <制約名> ] FOREIGN KEY (<列名>, ... , <列名> REFERENCES <親テーブル名> (<列名>, ... , <列名>) [ ON DELETE { CASCADE | SET NULL} ]
DEFAULT設定とNOT NULL制約はテーブルレベルで指定できない
外部キー制約を設定すると、親テーブルの参照キーにないデータを子テーブルの外部キーに登録できなくなる。
外部キー制約を設定する場合、親テーブルの参照キーは一意制約がなければならない。
外部キー制約を設定すると親テーブルの参照キーの値を更新できなくなる。
また、親テーブルの行は削除できない。但し、ON DELETE CASCADEが設定されている場合、子テーブルの行も削除される。ON DELETE SET NULLが設定されている場合は子テーブルの外部キーがNULLに設定される。
参照キーに自テーブルの列を指定することもできる。これを自己参照外部キー制約と呼ぶ。
制約を無効化/有効化するには、
ALTER TABLE <テーブル名> { DISABLE | ENABLE } CONSTRAINT <制約名>;
とする。
テーブルの変更
- ALTER TABLE ... ADD ...
- 列の追加
- 一番右側に列が追加される
- ALTER TABLE ... MODIFY ...
- デフォルト値の設定、データ型の変更、NOT NULL制約の追加/削除
- ALTER TABLE ... DROP ...
- 列の削除
- ALTER TABLE ... SET UNUSED ...
- 列の未使用化(削除に時間を要す売る場合の対処)
- ALTER TABLE ... UNUSED COLUMNS ...
- 未使用化した列の削除
- ALTER TABLE ... READ ONLY [ READ WRITE]
- 読み取りモード、読み書きモードへの変更
- ALTER TABLE ... MOVE TABLESPACE ...
- テーブルの移動
- ALTER TABLE ... RENAME TO ...
- テーブル名の変更
テーブルの削除
DROP TABLE ... [ CASCADE CONSTRAINTS ] [ PURGE ];
PURGEを指定するとゴミ箱へ入らずに完全に削除される。
FLASHBACK TABLE ... TO BEFORE DROP;
ゴミ箱に入っている表を復元する。
テーブルの切り捨て
すべての行を削除する。DELETE分よりも高速に行を削除できる。
TRUNCATE TABLE ... [DROP STORAGE | DROP ALL STIRAGE | REUSE STORAGE] [CASCADE];
ロールバック、フラッシュバック機能の対象外なので、一度TRUNCATEした後は戻すことができない。
- DROP STORAGE:表作成後に追加で割り当てられたストレージ領域が解放される。デフォルトの動作
- DROP ALL STORAGE:表に割り当てられたすべてのストレージ領域が解放される。
- REUSE STORAGE:表に割り当てられたストレージが解放されずに維持される。
CTAS
CREATE TABLE AS SELECTの略で、SELECT文を使用してテーブルを作成すること。
CREATE TABLE ... AS SELECT ...;
SELECT句のWHERE句に1=0といった常に偽になる条件を指定するとテーブル定義だけコピーできる。
一時表
セッションからのみ参照可能で、セッションが終了したら自動的に削除される。
セッションごとに独立して扱われる。
一時表領域に格納される。
REDOログの生成しない。
プライベート一時表(上記の特徴を持つ)とグローバル一時表の2種類がある。
グローバル一時表は表定義がデータベース全体で共通で、表定義がデータディクショナリに永続化される。
プライベート一時表のテーブル名はORA$PTT_で始まる名前にする必要がある。
CREATE PRIVATE TEMPORARY TABLE <ORA$PTT_で始まる表名>
...
ON COMMIT {DROP | PRESERVE} DEFINITION
[AS SELECT ...];
- ON COMMIT DROP DEFINITION:トランザクション終了時に自動的に一時表の定義とデータが削除
- ON COMMIT PRESERVE DEFINITION:セッション終了時に自動的に一時表の定義とデータが削除
グローバル一時表のテーブル名には制約なし。
CREATE GLOBAL TEMPORARY TABLE <表名>
...
ON COMMIT {DELETE | PRESERVE} ROWS
[AS SELECT ...];
- ON COMMIT DELETE ROWS:トランザクション終了時に自動的に一時表の定義とデータが削除
- ON COMMIT PRESERVE ROWS:セッション終了時に自動的に一時表の定義とデータが削除
外部表
例えば、ディレクトリにあるCSVファイル等をOracleのテーブルのように読み取ることができる。
CREATE TABLE ...
ORGANIZATION EXTERNAL
(
TYPE ORACLE_LOADER
DEFAULT DIRECTORY TEST_DIR
ACCESS PARAMETERS
(
fields terminated by ','
)
LOCATION('data.csv')
)
ビュー
SELECT文に名前をつけて保存したもの。
ビューへの参照権限のみを付与し、大元の実表にはアクセスさせないことで、データを保護できる。
CREATE VIEW <ビュー名> AS SELECT ... [WITH READ ONLY] [WITH CHECK OPTION]
ビューにアクセスする際はSELECT文でFROM句にビュー名を指定する。
ビューを削除するにはDROP VIEWを実行する。
DROP VIEW <ビュー名>;
WITH READ ONLYを指定しないと、ビューにDMLを実行可能になる。ビューに対してDMLを発行すると、ビューが参照している大元のテーブルのデータが変更される。
但し、ビュー定義のSELECT文に以下が含まれる場合はビューにDMLを発行することはできない。
集合演算子、DISTINCT演算子、集計ファンクション、GROUP BY、ORDER BY
WITH CHECK OPTIONを指定すると、ビューにDMLを発行したとき、変更後のデータがビュー定義のSELECT文のWHERE条件を満たしているかチェックされる。満たしてないとエラーになる。
INSTED OF トリガー
DMLを実行できないビューにINSTED OF トリガーを定義するとDMLを実行できる。
以下は、DMLを実行できない場合にDELETE文を実行する例。
CREATE TRIGGER <トリガー名> INSTEAD OF DELETE ON <ビュー名> BEGIN DELETE <テーブル名> WHERE ... ; END;
ユーザの作成
CREATE USER <ユーザ名> IDENTIFIED BY <パスワード> DEFAULT TABLESPACE <デフォルト表領域> QUOTA 10M on <表領域A> QUOTA UNLIMITED on <表領域B>
アクセス
他ユーザーが所有するオブジェクトにアクセスする場合、<スキーマ名>.<オブジェクト名>と記述する。
自ユーザーが所有するオブジェクトの場合、スキーマ名を省略できる。
権限とロール
権限にはシステム権限とオブジェクト権限の2種類がある。
システム権限
- CREATE SESSION(データベースへのログイン)
- CREATE TABLE
- CREATE USER など
オブジェクト権限
- SELECT
- INSERT
- DELETE など
システム権限の付与と取り消し
GRANT <権限名> TO <ユーザー> [WITH ADMIN OPTION]; REVOKE <権限名> FROM <ユーザー>;
権限はカンマ区切りで複数指定できる。
システム権限を付与するには、WITH ADMIN OPTIONを指定してシステム権限が付与されているか、GRANT ANY PRIVILEGEシステム権限が付与されていなければならない。
WITH ADMIN OPTIONを指定して付与されたシステム権限が取り消された場合でも、すでにWITH ADMIN OPTIONを利用して他ユーザーに付与したシステム権限は取り消されない。(取消しが連鎖しない)
オブジェクト権限の付与と取り消し
GRANT <権限名> [(列名)] ON <オブジェクト> TO <ユーザー> [WITH GRANT OPTION]; REVOKE <権限名> [(列名)] ON <オブジェクト> FROM <ユーザー>;
権限はカンマ区切りで複数指定できる。
列名を指定すると、指定した列にのみ権限を付与する。列名を指定しないと、オブジェクト全体に権限を付与する。
オブジェクト権限を付与するには、WITH GRANT OPTIONを指定してオブジェクト権限が付与されているか、GRANT ANY OBJECT PRIVILEGEシステム権限が付与されていなければならない。
WITH GRANT OPTIONを指定して付与されたオブジェクト権限が取り消された場合、WITH GRANT OPTIONを利用して他ユーザーに付与したオブジェクト権限も取り消される。(取消しが連鎖する)
ロール
複数の権限をひとまとめにしたもの。ロールに既存のロールを追加することもできる。
ロールを変更すると、ロールを付与しているユーザーに変更が反映される。
ロールの作成、ロールへの権限付与/取消、ロールの削除は次の通り。
CREATE ROLL <ロール名>; GRANT <権限> TO <ロール名>; REVOKE <権限> FROM <ロール名>; DROP ROLL <ロール名>;
ユーザーへのロールの付与/取消
GRANT <ロール名> TO <ユーザー名>; REVOKE <ロール名> FROM <ユーザー名>;
PUBLICロール
事前作成済みの特殊なロール。
PUBLICロールに権限を付与すると、すべてのユーザーに権限が付与される。
データディクショナリ
Oracle内部の管理情報を格納している表。表などのオブジェクト定義やユーザー情報、ロール/権限の情報などが格納されている。
SYSユーザーが所有し、SYSTEM表領域に格納している。
データディクショナリビューに問い合わせることで管理情報を参照できる。
主なデータディクショナリビュー
- DBA_TABLES
- DBA_INDEXES
- DBA_VIEWS
- DBA_SEQUENCES
- DBA_SYNONYMS
- DBA_CONSTRAINTS
- DBA_USERS
- DBA_TABLESPACES
タイムゾーン
DATE型とTIMESTAMPがたはタイムゾーンに対応していない。
TIMESTAMP WITH TIME ZONE型またはTIMESTAMP WITH LOCAL TIME ZONE型を使用する。
TIMESTAMP WITH TIME ZONE型
- 記録されたタイムゾーンは INSERTしたセッションのタイムゾーンの時刻で記録される。タイムゾーン情報(例:ASIA/TOKYO)も記録される。
- 記録したデータを他のタイムゾーンから参照した場合、記録時のタイムゾーンの表記で読みだされる。
TIMESTAMP WITH LOCAL TIME ZONE型
- データはUTC時刻に正規化されて記録される。
- 参照時にセッションのタイムゾーンに従って変換される。例えば、セッションのタイムゾーンがUTC+9:00であれば、ASIA/TOKYOタイムゾーンの時刻を表示する。
- セッションのタイムゾーンはクライアントプログラムの実行環境から自動的に決定される。