概要
UdemyのAirflow講座で勉強したことのメモ。
この記事では主に事前設定やコードについて記載。
(事前準備)Dockerが重たいので、Airflow Standaloneで乗り切る
Udemyの講座ではDockerを使って、AirflowだけでなくPostgresSQLなどのコンテナも動かすので、自分の貧弱なPCスペックではメモリがいっぱいになってしまった。
そこで、Airflow Quick Startで利用したairflow standalone コマンドで余計なリソースはいっさい起動しないようにした。
だが、講座で扱うコードの中で、PostgreSQLが登場するので事前にPostgreSQL自体や、PostgreSQL Providerをインストールしておく。
# PostgreSQLをインストール sudo apt install postgresql # libpq-devをインストール # !!注意!!:これをインストールしておかないと、PostgresSQLプロバイダーのインストールに失敗した sudo apt install libpq-dev # PostgresSQLプロバイダーをインストール pip install apache-airflow-providers-postgres # PostgresSQLを起動 sudo service postgresql start # ユーザー「postgres」になる sudo -u postgres -i # PostgreSQLに入る psql # DB「airflow_db」を作成 CREATE DATABASE airflow_db;
PostgreSQLの参考コマンドはこちら。こちらを参考にしてDBが作成されていることを確認する。
Airflow UIでConnectionsの設定
Airflow UIでConnectionsの設定をする。
PostgreSQLの接続情報
上記で作成したPostgreSQLのユーザー、パスワード、DB(Schema)を設定

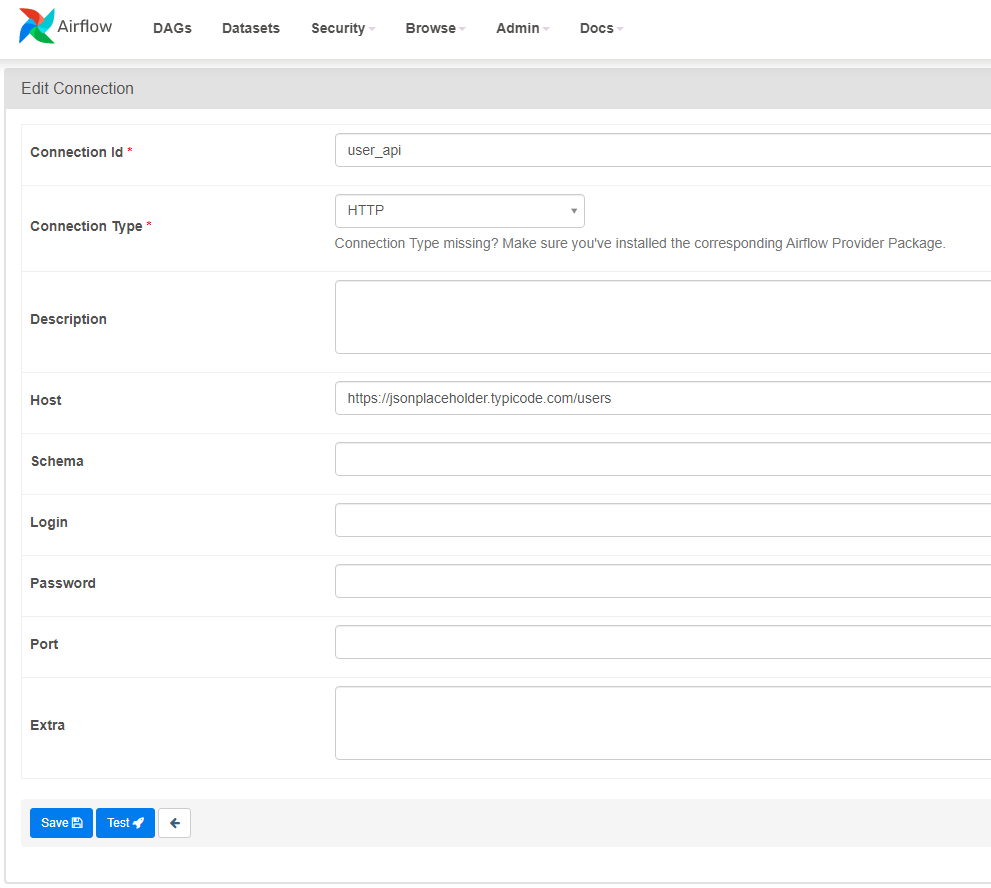
HTTPの接続情報
Udemy講座内で設定したものとは異なるAPIエンドポイントを使ってます。
Airflowのコードを書く
~/airflow/dags配下にuser_processing.pyを作成する。5分以内にAirflow UIのDAGs viewに表示される。

コードの説明は、コード内のコメントを参照のこと。
user_processing.py
from airflow import DAG
from airflow.providers.postgres.operators.postgres import PostgresOperator
from airflow.providers.http.sensors.http import HttpSensor
from airflow.providers.http.operators.http import SimpleHttpOperator
from airflow.operators.python_operator import PythonOperator
from airflow.hooks.postgres_hook import PostgresHook
from datetime import datetime
from pandas import json_normalize
import json
# タスクの持っている属性値を取り出すには引数にtiと記述する(詳細はよくわかってません)
def _process_website(ti):
# XCOMでタスク間でメッセージをやり取りする
# タスク"extract_website"の値を受け取る
users_from_website = ti.xcom_pull(task_ids="extract_website")
users = users_from_website[0]
# JSONに編集する
processed_user = json_normalize({
'firstname': users['name'],
'lastname': users['username'],
'country': users['address']['city'],
'username': users['username'],
'password': users['username'],
'email': users['email'] })
# CSVファイルに書き込む
processed_user.to_csv('/tmp/processed_website.csv', index=None, header=False)
def _store_user():
# PostgresHookで、CSVファイルから取り出したデータをPostgreテーブルにコピー
hook = PostgresHook(postgres_conn_id='postgres')
hook.copy_expert(
sql="COPY test_table FROM stdin WITH DELIMITER as ','",
filename='/tmp/processed_website.csv'
)
# DAGを定義する
# 'user_processing'はDAGのID。Airflowのクラスター内でユニークでなければならない
with DAG('user_processing', start_date=datetime(2022,9,28), schedule_interval='*/1 * * * *',catchup=False) as dag:
# task_idはDAG内でユニークでなければならない
# PostgresOperatorでPostgreSQLに接続し、SQLを実行する
# PostgreSQLの接続情報はAirflow UI上のConnectionsで定義しておく
# postgres_conn_idで設定した値がConnectionsの識別子となる
create_table = PostgresOperator(
task_id="create_table",
postgres_conn_id="postgres",
sql='''
CREATE TABLE IF NOT EXISTS test_table (
firstname TEXT NOT NULL,
lastname TEXT NOT NULL,
country TEXT NOT NULL,
username TEXT NOT NULL,
password TEXT NOT NULL,
email TEXT NOT NULL
);
'''
)
# HttpSensorはAPIエンドポイントが稼働しているかチェックする
# HTTPのエンドポイント情報はAirflow UI上のConnectionsで定義しておく
is_api_available = HttpSensor (
task_id="is_api_available",
http_conn_id="user_api",
endpoint="" # APIエンドポイントのパスを記述する。今回はパス指定なし
)
# こちらのSimpleHttpOperatorではAPIエンドポイントに対してGETした結果をresponse_filterに格納している
# response_filterでは格納する前に処理できる。ここではJSONに変換している
extract_website = SimpleHttpOperator(
task_id="extract_website",
http_conn_id="user_api",
endpoint="", # エンドポイントURLのパスを指定する
method="GET",
response_filter=lambda response: json.loads(response.text),
log_response=True
)
# PythonOperatorを使って、関数_process_website()を呼び出している
process_website = PythonOperator(
task_id='process_website',
python_callable=_process_website
)
# PythonOperatorを使って、関数_store_user()を呼び出している
store_user = PythonOperator(
task_id='store_user',
python_callable=_store_user
)
# タスクの実行順序を>>を使って定義している
create_table >> is_api_available >> extract_website >> process_website >> store_user