1. I spent 3 hours figuring out how BigQuery inserts, deletes and updates data internally. Here’s what I found.
ライトノベルのようなタイトルですね。BigQuery内部でどのようにファイルを管理しているかキレイな図で紹介してくれてます。
データを挿入、削除するときに既存のファイルを書き換えるのではなくて、新しいファイルを作成し、ファイル抽象化層(Storage set)で古いファイルへの参照をやめて、新しく作成されたファイルを参照します。
つまり、一度作成されたファイルは不変で、データを書き換える必要がある場合は常に新しいファイルを作成するということ。古いファイルは、タイムトラベル(過去の時点のデータを参照する機能)で使用しますが、タイムトラベル保持期間を過ぎると、古いファイルはガベージコレクションとしてラベリングされるようです。
2. Lesson learned after reading the BigQuery academic paper: Shuffle operation
Map-ReduceからBigQuery(Dremelエンジン)への進化について説明してくれてます。
Map-Reduceでは、Mapperであるマシンは、ローカルのストレージ(メモリやディスク)を使用していたのに対し、BigQueryで使用されるDremelエンジンではストレージをマシンと分離してます。
3. BigQuery Admin reference guide: Query processing
こちらではBigQueryでどのようにクエリが処理されるかの概要が説明されています。

4. BigQuery Admin reference guide: Query optimization
こちらはGCP公式のBigQueryでの最適なクエリの書き方についての記事です。
- WHERE句内の式の順序は、レコード数をより削減できる条件を先に持ってくる。
- 結合では、最初に最大のテーブルを持ってくる。(結合の並び替えは特定の条件下でのみ行われるため、ユーザー側で結合の順序を意識することが重要)
- 結合前にWHERE句で可能な限りレコード数を少なくする。
- パターンマッチングの場合、
=<LIKE< 正規表現 の順で処理が重くなる。 WITH句ではなく、一時テーブルを使用する。WITH句のエイリアスが参照される度に、サブクエリが実行される。
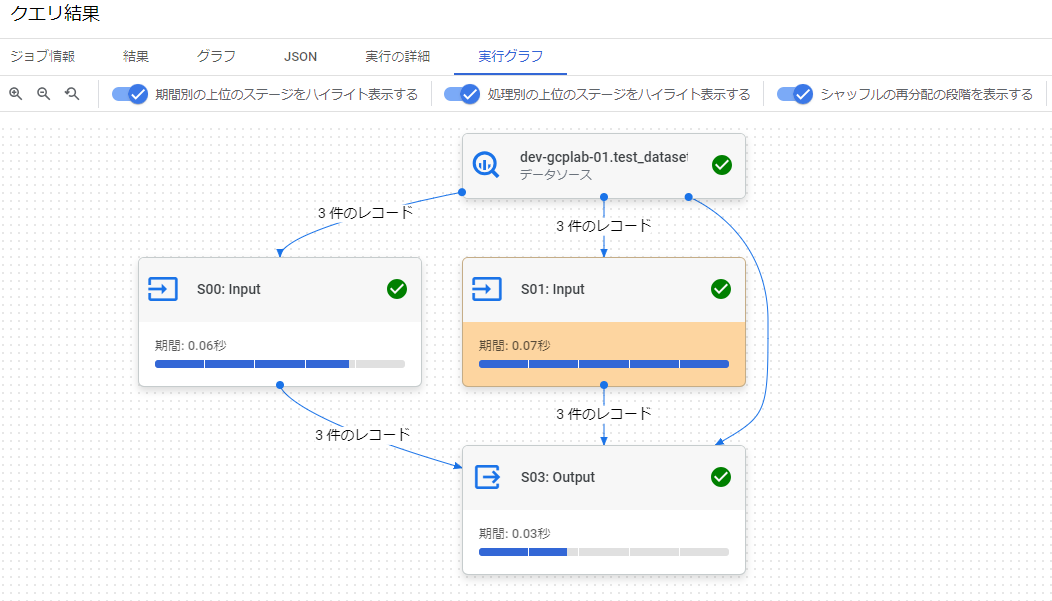
こちらについては本当にそうなるのか疑問だったので実行してみた。
WITH s AS ( SELECT * FROM `dev-gcplab-01.test_dataset.staff` ) SELECT * FROM s AS a JOIN s AS b ON a.id = b.id JOIN s AS c ON a.id = c.id↑のようにWITH句のサブクエリをJOINで繰り返し参照すると、確かにInputが2つ+データソース1つで、入力が計3つになった。
同一idで最新のレコードを取り出すといった場合には、ROW_NUMBER関数よりもARRAY_AGGを使用する。
ROW_NUMBER
sql WITH t AS ( SELECT * ,ROW_NUMBER() OVER( PARTITION BY id ORDER BY updated_at DESC) rn FROM test_dataset.purchase ) SELECT * EXCEPT(rn) FROM t WHERE rn = 1;ARRAY_AGG
sql SELECT ARRAY_AGG( s ORDER BY updated_at LIMIT 1 )[OFFSET(0)] FROM test_dataset.purchase s GROUP BY id;
YouTubeにあげられている動画も参考になりそう