概要
AirflowのTutorialをやっても、短時間で理解できなさそうだったのでUdemyの講座を試してみました。
英語の講座だったのでちょっとしんどかったので、半分くらいのとこまでしかやってません。
超初歩はなんとなくわかりました。
https://www.udemy.com/course/the-complete-hands-on-course-to-master-apache-airflow
と、いうことで以下ざっくりメモ。理解間違ってたらすみません。
コードは別記事にします。
Airflowのええとこ
コアコンポーネントは以下の4つ。
- Webサーバ:AirflowのUI。Flaskで出来ている。
- Scheduler:タスクをWorkerに渡す
- Metastore:SQL AlchemyとコンパティブルなDBであればOK。たとえば、Postgres、MySQL、Oracle DB、SQL Serverなど。メタデータストアには、データパイプラインやタスク、Airflowユーザなどのメタデータが保存される。
- Triggerer:Triggererは特定のタスクを実行する。詳細は後程。
それ以外のコンポーネント。
- Executor:K8sクラスタであればK8s用のExecutorが必要だし、Celery(*1)であればCelery用Executorが必要。
- Queue::タスクを入れておくためのキュー
- Worker:タスクを実行する
(*1):Celeryは分散処理のPythonフレームワークらしい。
Airflowで登場する概念
- Workflow:DAG、オペレーター、タスクをまとめた概念がワークフロー。ワークフローは1つ以上のDAGから成る(たぶん)。
- Task / Task instance: Taskは、Operatorを実行する際の呼び名。Task instanceは、よくわからないけれど、Taskが処理されたときに実体化する?
- Operator:オペレーターには次の3種類がある。
- Actionオペレーター:例 BashOperator
- Transferオペレーター:データの移転を行う。例えばMySQLからRedshiftへのデータトランスファーなどを行う。
- Sensorオペレーター:処理をするのを待ってくれる。例えば、ファイル処理を待つFileSensorなどがある。
- DAG:タスク間の順序を定義する。
シングルノードアーキテクチャ
- 1つのマシン上でAirflowを動かす最もシンプルなアーキテクチャ。
- タスクは、マシンのプロセスによって処理される。
マルチノードアーキテクチャ
- 本番環境ではこちらを使う。冗長性があり、大規模なワークロードも実行できる。
- マルチノードで処理させるために、CeleryやK8sを使う。
- 1つ目のノードにはWebサーバ、SchedulerとExecutorがあり、2つ目のノードにMetastoreとQueueがある。さらにWorkerノードがある。
- ExecutorがタスクをQueueに入れて、各WorkerノードがQueueからタスクをプルする。
- Celery Executorの場合、QueueにはRabbit MQかReddisを使う。
- Celery Workerノードは、
airflow celery workerコマンドで起動できる。
Airflowの動作
- SchedulerがDAGを起動すると、
RunningステータスのDAG Runオブジェクトが作成される。
- DAG Runオブジェクトが最初のTaskを実行すると、そのTaskがTask Instanceオブジェクトになる。
- Task Instanceオブジェクトはまず
Noneステータスだが、すぐにScheduledステータスになる。
- その後、SchedulerがTask InstanceオブジェクトをExecutorのQueueに送る。
- Queueに追加されたTask Instanceオブジェクトのステータスは
Queuedになる。
- そして、Executorがタスクを実行するためにサブプロセスを作成する。
- すると、タTask Instanceオブジェクトは
Runningステータスになる。
- タスクが完了すると、Task Instanceオブジェクトのステータスは
SuccessまたはFailedとなる。
- そして、Schedulerは実行すべきタスクがないかを確認して、もしタスクがない=DAGが完了している場合には、DAG Runオブジェクトが
Successステータスになる。
- Web UIでDAG RunオブジェクトとTask Instanceオブジェクトのステータスを確認できる。
DAG Runのステータス遷移
Running → Success / Failed
Task Instanceオブジェクトのステータス遷移
None → Scheduled → Queued → Running → Success / Failed
Airflowコードの配置場所
- Airflowのコードを
.pyファイルで作成したら、dagsフォルダに格納する。
- 但し、
~/airflow/dagsフォルダに入れても、すぐにはAirflow UIに反映されない。
- Schedulerは5分間隔でDAGフォルダを確認して、
.pyファイルがあればパースし、Airflow UIに反映する。
- また、Schedulerは30秒間隔でファイルの修正をパースするので、Airflow UIに反映されるまで最大で30秒要する。
Airflow UI
各Viewで確認できることについて説明する。
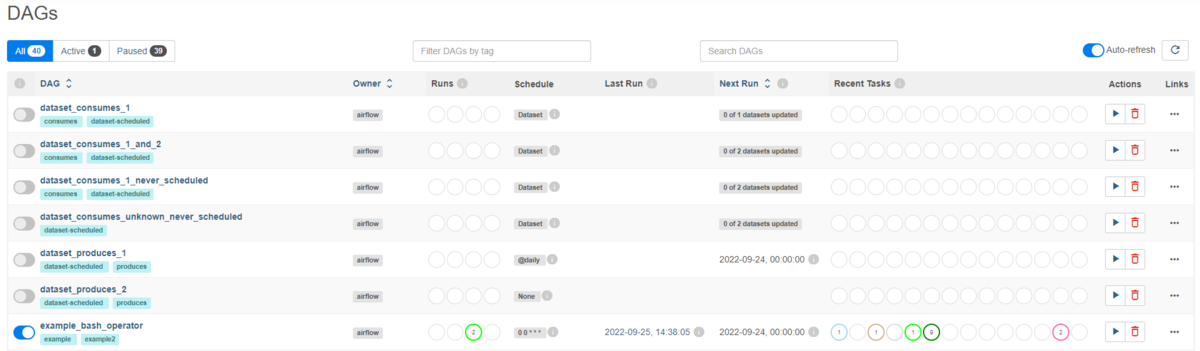
DAGs view
- トグル:DAGの開始、停止
- DAG名
- タグ
- オーナー
- Runsステータス:DAG Runsオブジェクトのステータス
- Schedule:cron風の起動時刻設定(※ Cronとは意味合いが違うので要注意)
- Last Run:最後にDAGを実行した時間
- Next Run:次回にDAGを実行する時間
- Recent Tasks:実行したタスクのステータス
- Actions:DAGの開始、DAGメタデータの削除
- Links
Landing view
- DAG実行に要した時間を日次でプロットしている。
- DAGの実行時間をどの程度短くなったか(あるいは長くなったか)を評価できる。
- 例えば、ワーカーインスタンスを増やした結果、どれくらい要した時間が減少したかを確認できる。
Gantt view
- タスクごとにどれくらい時間を要したかをガントチャート形式で表示。
- タスクが時間的に重なって実行されている時は、並列処理されていることを示している。
- ガントチャートが直列処理しているように見える場合には、並列処理になるよう修正が必要。
Code view
- DAGのコードを表示。
- 修正したコードが反映されているか確認する。
Graph view
- タスク間の依存関係がわかる。
- タスクの枠の色からタスクの実行結果がわかる。
DAG (Directed acyclic graph) 用語
- Node:タスクを意味する。
- Edge:タスク間の依存関係を意味する。
Operatorを定義する際の注意
処理とOperatorを1対1で対応させる。
例えば、データクリーニングとデータ加工を同じ1つのPythonオペレーターで処理しようとする場合、データ加工が失敗したのでリトライしようとするが、オペレーターにはデータクリーニングも含まれているので、リトライ時にデータ加工だけでなく処理が成功済みのデータクリーニングも再度実行してしまう。
Providerについて
Airflowはモジュラー・アーキテクチャになっている。
Airflowをインストールした段階では、PythonオペレーターやBashオペレーターといった主要なオペレーターしかインストールされない。
例えば、AWSのオペレーターを利用したい場合には、Amazonプロバイダーをインストールする必要がある。
利用したいプロバイダーをそれぞれインストールしていく。
どんなプロバイダーがあるかは、以下を参考にすると良い。
https://registry.astronomer.io/
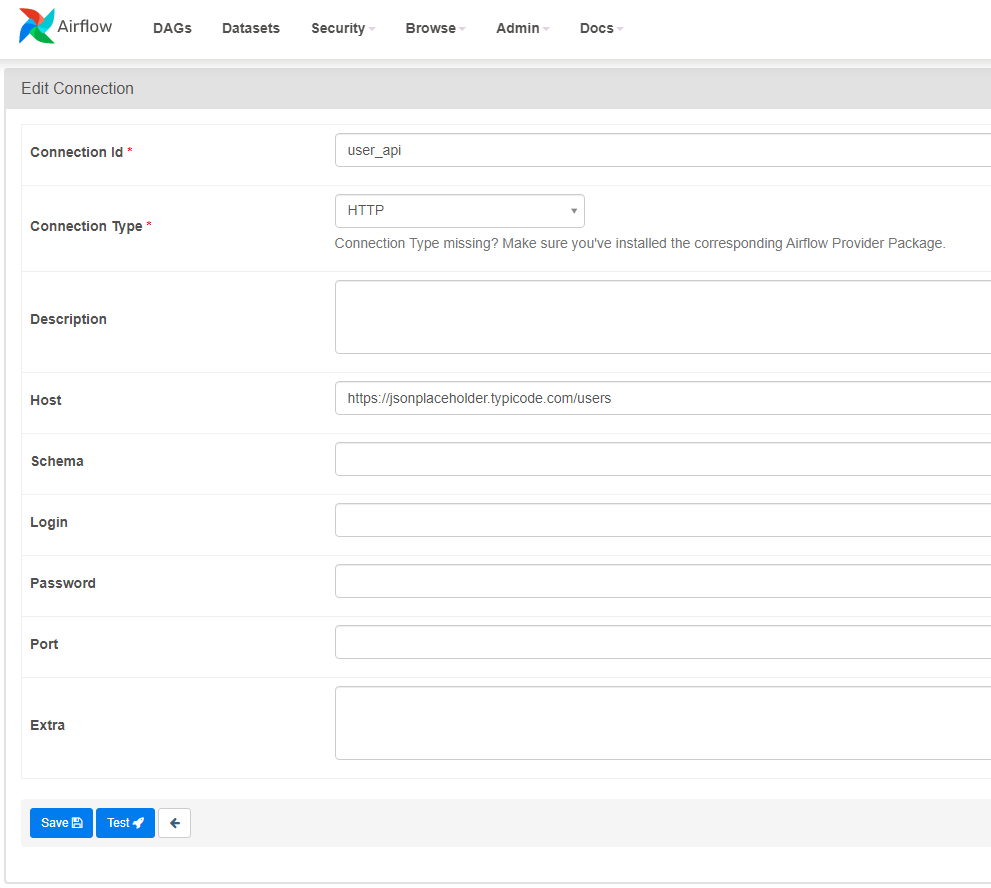
Connectionsについて
DBなどの接続情報はAirflow UI上で登録できる。
Airflow UIのAdminタブからConnectionsを選択し、新しく接続情報を登録する。
Sensorについて
Sensor関連の重要パラメータ
poke_interval
- デフォルトで60秒間隔でSensorが条件を満たしているかチェックする。
timeout
- デフォルトで7日間に設定されている。7日間待機しても条件を満たさない場合はFailedとなる。
Sensorの例
HTTP Sensor:APIが稼働しているかどうかをチェックする。
Hookについて
外部との接続を抽象化して、簡易に接続ができるようにしてくれる。
オペレーターで接続できない場合は、Hookで接続できないか確認してみるのがよい。
タスク間の依存関係の指定
>> または << を利用して表す。
extract_website >> process_website >> store_user のような感じ。
extract_website = SimpleHttpOperator(
...
)
process_website = PythonOperator(
...
)
store_user = PythonOperator(
...
)
extract_website >> process_website >> store_user
あるいは、set_upstreamとset_downstreamを使う。
DAGを分岐させるにはBranch Operatorを利用する。こちらを参照のこと。
DAGのスケジュール
DAGを2分間隔で実行したい場合は、/2 * * * のように記述する
dag = DAG("tutorial", ..., schedule_interval="*/2 * * * *")
Backfillingメカニズム
airflow dags backfillコマンドを利用すると、start_date以前の期間に対してDAGを実行してくれる。
Catchupメカニズム
catchup=Trueとすることで、start_date以降で実行していないDAG Runがあれば、遡って実行してくれる。
with DAG('tutorial',..., catchup=True) as dag:
コンフィグ
Executor等を変更するには、airflow.cfgコンフィグファイルの内容を編集する。
コンフィグファイルの内容は環境変数でオーバーライドできる。例えば、環境変数AIRFLOW__CORE__EXECUTOR で、Executorの設定を上書きできる。
Executorの種類
Sequential Executor
1つのタスクのみしか一度に処理できない
LocalExecutor
SQLLiteを使用していると、Sequential Executorしか使えない。
SQLLiteではなく、PostgresSQLやMySQLを使用することで、LocalExecutorを利用できるようになる。
LocalExecutorもSequentialExecutorと同じくWorkerは1つのみだが、マルチプロセスにより複数のタスクを並列で処理ができる。
つまり、LocalExecutorはスケールアップ(スケールアウトではない)により、より多くのタスクを並列処理できるようになる。
LocalExecutorを利用する場合は次のようにコンフィグを設定する。
executor=LocalExecutor
sql_alchemy_conn=postgresql+psycopg2://<user>:<password>@<host>/<db>
CeleryExecutor
Celearyを使って、複数のWorkerでタスクを処理する。
CelearyExecutorの場合、CelearyQueueというのがアーキテクチャのコンポーネントとして存在する。
このCeleary Queueには、BrokerとResultBackendという2種類のDB(?)が存在する。
BrokerはSchedulerからタスクを受け取って、それをWorkerに割り振る。
Workerで処理が終わったら、処理結果をResultBackendに保存する。
CelearyExecutorを利用する場合の設定は次の通り。
executor=CeleryExecutor
sql_alchemy_conn=postgresql+psycopg2://<user>:<password>@<host>/<db>
celery_result_backend=postgresql+psycopg2://<user>:<password>@<host>/<db>
celery_broker_url=redis://@redis:6379/0
豆情報
airflow.cfgでload_examples = Falseとすると、DAGの例がAirflow UIに表示されなくなる。
Sub DAG
【重要】SubDAGは複雑なので、Airflow 2.2で非推奨となった。SubDAGではなく、Task Groupを使う。
SubDAGで複数のタスクを1つのサブDAGとしてまとめることができる。
タスクを1つにまとめることで運用が楽になる。
Subdagを利用するには以下が必要。
- dagsフォルダの配下にsubdagsフォルダを作成する。
- subdagsフォルダ内に、.pyファイルを作成し、そこに関数を定義する。
- 関数の引数はparent_dag_id, child_dag_id, argsの3つ。
- 関数内にDAGを定義する
with DAG (f"{parent_dag_id}.{child_dag_id}", ... ) as dag:
...
return dag
- メインとなる
.pyファイルにSubDAGOperatorでSubDAGを呼び出す。
Task Group
- dagsフォルダの配下にgroupsフォルダを作成する。
- groupsフォルダ内に、.pyファイルを作成し、そこに関数を定義する。
- 関数の引数は不要。
- 関数内にTaskGroupを定義する
with TaskGroup ("task_group_id", tooltip="hogehoge") as group:
...
return group
- メインとなる.pyファイルで、定義した関数を呼び出す。